 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|||||||||
| PREV NEXT | FRAMES NO FRAMES | ||||||||
See:
Description
| Packages | |
|---|---|
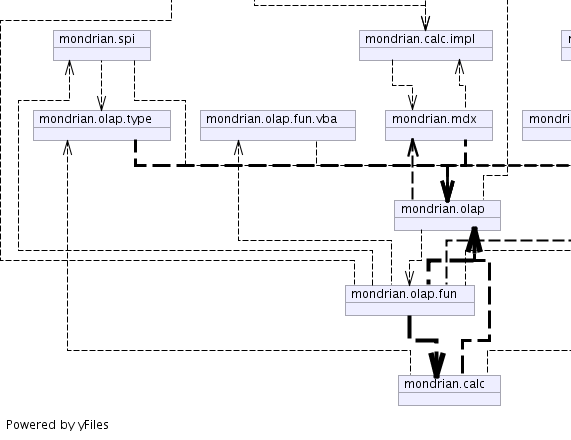
| mondrian.calc | Provides compiled expressions. |
| mondrian.calc.impl | Provides implementation classes for compiled expressions. |
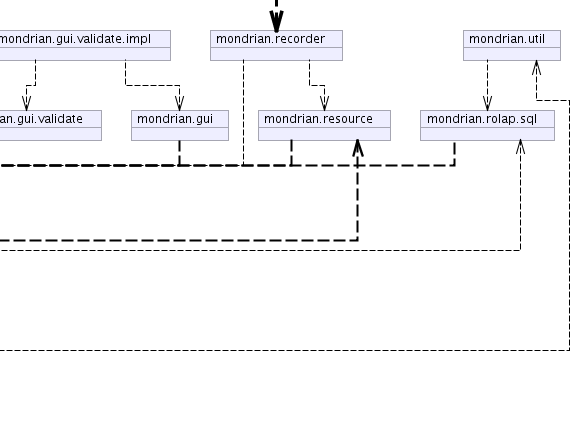
| mondrian.gui | Contains a workbench written in Swing for designing Mondrian schemas. |
| mondrian.gui.validate | |
| mondrian.gui.validate.impl | |
| mondrian.i18n | Utilities for internationalization and localization. |
| mondrian.mdx | Defines a parse tree for MDX expressions. |
| mondrian.olap | Mondrian's core package, this defines connections and the catalog metamodel, and allows you to execute queries. |
| mondrian.olap.fun | Defines the set of MDX built-in functions. |
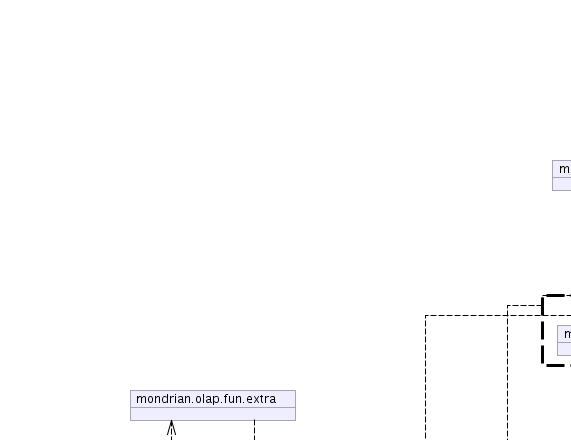
| mondrian.olap.fun.extra | Defines MDX extension functions. |
| mondrian.olap.fun.vba | Implements the set of functions defined by the Visual Basic for Applications (VBA) specification. |
| mondrian.olap.type | Type system for MDX expessions. |
| mondrian.olap4j | olap4j driver for the Mondrian OLAP engine. |
| mondrian.recorder | Provides a set a classes for logging the process of a task. |
| mondrian.resource | |
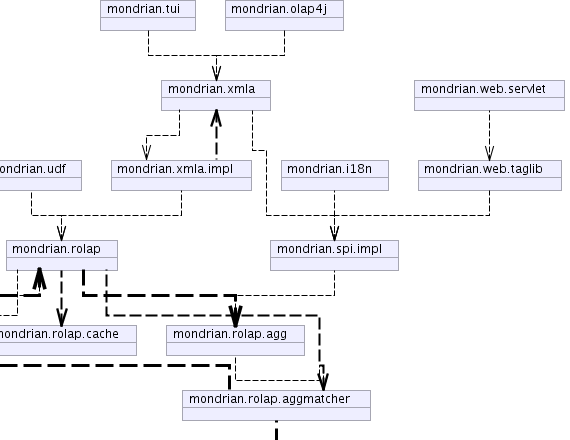
| mondrian.rolap | Implements the data access layer for the olap package. |
| mondrian.rolap.agg | Manages a cache of aggregates containing cell values. |
| mondrian.rolap.aggmatcher | Defines a 'matcher' which scans the schema to find candidate aggregate tables. |
| mondrian.rolap.cache | Provides primitives for policy-based caching. |
| mondrian.rolap.sql | Database-independent library for generating SQL. |
| mondrian.spi | Contains the server-provider interfaces (SPIs) which user-defined extensions to Mondrian should implement. |
| mondrian.spi.impl | Provides implementations of SPIs defined in the mondrian.spi package. |
| mondrian.tui | Text user interface for Mondrian. |
| mondrian.udf | |
| mondrian.util | Mondrian utilities. |
| mondrian.web.servlet | |
| mondrian.web.taglib | Provides a tag library for embedding MDX queries in JSP pages. |
| mondrian.xmla | Implements the XML for Analysis API. |
| mondrian.xmla.impl | |
Mondrian is an OLAP server implemented in Java.
See architecture.
See Parser.
It is represented as an XML file. The metadata is loaded into memory the
first time you reference a dimensional model. You can modify the model at
runtime by creating instances of classes such as RolapHierarchy
todo: The package . is the one and
only implementation of the API. The DriverManager (mondrian.rolapclass ) acts as class-factory.DriverManager
todo: How members are calculated...
todo: How aggregations are batched...
todo: MDX functions. See user-defined functions.
Aggregations are based upon the relational model: as far as the aggregation
manager is concerned, there is no relationship between the columns city
and state. This means that all roll-ups are the same: you just drop
a column. Consider the 3 roll-ups possible by dropping a column from the
aggregation {gender, city, state}:
dropping gender is equivalent to removing the [Gender]
dimension; dropping city is equivalent to rolling up to a higher
level in the [Geography] hierarchy; and dropping state
is not even allowed in the dimensional model (no, sorry, you can't ask about
products sold in a cities called 'Portland'). This approach will also allow us
to implement 'drill anywhere'.
An aggregation is defined by a search condition, for example, {state in
('CA', 'OR', 'WA'), city = any, gender = 'M', measure = 'Unit sales'}.
The any value is important; if we had asked for a specific
set of cities, we would not later be able to roll-up by dropping the city
column.
The caching strategy is to throw out the aggregation with the lowest cost/benefit ratio. The 'benefit' of an item is the effort it took to produce (effort which it is saving future queries) multiplied by its 'usefulness' which declines exponentially if it is not used over time. The 'cost' of an item is its size.
| $Id: //open/mondrian/src/main/overview.html#6 $ (log) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
| PREV NEXT | FRAMES NO FRAMES | ||||||||